
Case Study: Predicting Human VDss in Discovery
OpenBench's deep learning platform outperforms conventional methods

ADME Talks is a newsletter democratizing the cutting edge in virtual ADME-Tox, pun intended.
As always, we share our analysis in the opnbnchmark Github repository. The companion Jupyter notebook for this piece can be found here:
Were you forwarded this post? Please subscribe:
Executive Summary
A machine learning (ML) model trained from the literature to predict steady-state human volume of distribution (VDss) matches the quality of rodent PK-based prediction on a 105 compound test set compiled by Petersson et al. (2019). Analysis supports that the OpenBench Lab is an accurate, animal-sparing solution for the assessment of human VDss during discovery and lead optimization.
Introduction
Human volume of distribution at steady state (VDss) is a crucial pharmacokinetic parameter used to establish the starting dose of a small molecule drug in clinical trials. Due to its importance, scientists have developed a range of methods to estimate the volume of distribution of a drug before it is ever administered to a human being. In a 2019 article, Petersson et al. of Merck KGaA compare the accuracy of eight such estimation methods, differentiating between approaches that predict VDss from data available during discovery and lead optimization (rodent pharmacokinetic (PK) data, free fraction in plasma, blood:plasma ratio, and physicochemical characteristics) and those that further depend upon dog and monkey in vivo PK data, which typically become available only during preclinical development.

Petersson et al. compare the various estimation methods using an exemplary test set of 106 compounds compiled from the literature. In the discovery setting, they determine single species scaling of rat PK typically works best for basic, zwitterionic, and neutral compounds. Accurate VDss assessment of acidic compounds favors the PBPK-based Rodgers-Ludcova method. In preclinical development, as more in vivo PK data becomes available, applying the Øie-Tozer equation to rat plus at least one other non-rodent species’s data outperforms all other methods for estimating VDss across ion classes.
Particularly in the discovery use case, it is of great interest and value to build an in silico method to predict VDss that will spare animals and save time and money when iterating on hypotheses relating compound structure and distribution properties. The OpenBench Lab platform was built to take on precisely this sort of problem.
Training Data
To learn a mapping between chemical structure and a pharmacologically relevant property like VDss, machine learning models like those trained and deployed in the OpenBench Lab extract information and latent patterns from labelled data. With the intention of training such a model, a data set was collected from three different literature sources: Obach et al. (2006), Lombardo et al. (2018), and Berellini and Lombardo (2019).
All compounds in the Petersson et al. test set were deliberately removed from the collected training set to avoid cross-contamination. The data cleaning process is outlined in the companion Jupyter notebook and the resulting cleaned training set is available in the opnbnchmark Github repository.
Analysis
We predict human VDss and benchmark results alongside the range of methods reported upon in Petersson et al. We reproduce three metrics described in the paper to compare approaches:
Average Absolute Fold Error (AAFE): This metric measures the precision of a given method. It is equivalent to the geometric mean of the fold error between predicted and experimental values. The larger the absolute error, the further away from the truth predictions lie from ground truth in aggregate.

Lifted directly from Petersson et al. (2019) % within 2-fold: Another metric measuring accuracy of a predictive approach. This captures the percentage of predictions that fall within 2-fold of the true experimental value. The higher the value, the better the predictions are.
Average Fold Error (AFE): A bias metric that indicates whether a method systematically over- or under-estimates experimental human VDss. A value of 1.0 suggests no bias. Values significantly greater or less than 1.0 indicate over- and under-estimation respectively.

Lifted directly from Petersson et al. (2019)

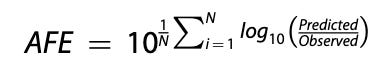
Prediction
Human VDss was inferred on the Petersson et al. test set with the exception of one compound labelled “cmet orange,” for which it wasn’t possible to confirm a SMILES representation. It was the only compound without external reference in the Petersson et al. Supplemental Information. The resultant predictions are summarized in the plot below. The black line in the plot indicates the x=y unity line along which all points would be organized with a perfect predictor. The golden dashed lines represent the two-fold error band around experimental ground truth.

The OpenBench Lab outperforms all VDss prediction methods designated by Petersson et al. as accessible in discovery, including those that use in vivo rat PK data. Recall, lower AAFE values describes better precision, and an AFE as close as possible to 1.0 is desirable.

Applying Øie-Tozer to multi-species (Rat-Dog-Monkey) data in preclinical development reigns supreme on the Petersson et al. test set as the gold standard for human VDss estimation in preclinical development. Nonetheless, as seen in Figure 2, the wholly in silico OpenBench Lab outperforms many accepted techniques historically deployed for VDss prediction in preclinical development. A permutation test comparing the AAFE of OpenBench’s methods to multi-species Øie-Tozer cannot reject the null hypothesis that the difference in AAFE between methods is 0 at a significance level of α = .05.

Discussion
While the Petersson et al. benchmark is not exhaustive, the OpenBench Lab’s predictive capacity relative to other methods available in discovery is undeniable. It is particularly impressive when one considers that no in vitro or in vivo data needs to be generated to make these wholly in silico predictions. The OpenBench Lab infers human VDss from structure alone at the click of a button.
OpenBench is on a mission to bring the cutting edge in machine learning for molecular property prediction to discovery scientists everywhere. If you are interested in joining the pharmaceutical and biotech companies using OpenBench to make their drug discovery programs more resource efficient, sign up for a trial today. If you register before January 1, 2021, OpenBench will model an ADME-Tox endpoint of your choosing and test it in the chemical space that matters most: your own. Sign up today:
Acknowledgements
This case study would not be possible without the groundwork laid by Petersson and colleagues of Merck KGaA. We express our sincere gratitude for their research as well as the careful construction and sharing of this benchmark.
We are deeply grateful to the authors and researchers who contributed to crafting the curated data sets from which training data for this case study was collected. Special thanks to Scott Obach, Franco Lombardo, Giuliano Berellini, and colleagues.
Compliments to Pat Walters of Practical Cheminformatics for his notes on attractive and informative seaborn plots.
Excellent!