
Case Study: Predicting hERG Liability in Novel Chemical Space
A Retrospective Lead Optimization Case Study

Executive Summary
In this retrospective analysis of a CCR5 antagonist program seeking to reduce hERG affinity, the OpenBench Lab delivers hERG inhibition predictions with actionable accuracy in novel chemical space. These predictions improve with iterative fine tuning, offering an illustrative anecdote of how the OpenBench Lab can act as a compound triage tool for drug discovery teams deciding how to efficiently spend their in vitro ADME-Tox budget.
Introduction
This is part 1 of a retrospective and hypothetical case study illustrating how the OpenBench Lab could have been used to support the discovery efforts described in Cumming et al. (2012), a lead optimization that aims to reduce hERG affinity while maintaining favorable absorption, distribution, metabolism, and excretion (ADME) properties in a CCR5 antagonist program. This study offers an illustrative anecdote of how the OpenBench in silico ADME-Tox Lab can help scientists improve clinically relevant properties of lead series by using the Lab’s state-of-the-art predictive models at the click-of-a-button. For the sake of completeness and reproducibility, all experimental results, training data, and predicted values from the OpenBench ADME-Tox Lab v0.0 are included in a public Github repo. To try the OpenBench Lab for yourself, join a trial at our website:
The Hunt is On!
Our tale begins with John Cumming and his audacious fellow investigators at AstraZeneca sailing into open chemical waters in hot pursuit of a new class of small molecule CCR5 antagonists, which they hope will effectively treat rheumatoid arthritis. Before long, the team runs into a common charybdis faced by those who attempt to target CCR5. Alongside excellent CCR5 potency (IC50 = .32 nM), their lead compound 1 shows moderate hERG K+ channel (IC50 = 7.3 μM) activity, which indicates cardiotoxicity risk potential. In the authors’ own words:
Inhibition of the hERG channel is a common challenge for medicinal chemists developing drugs acting at CCR5 and at chemokine receptors generally due to pharmacophoric features shared with hERG blockers.

Tacking into the hERG headwind, the audacious team plots a course to “identify a potent and selective CCR5 antagonist with good oral PK properties and hERG channel binding IC50 > 30μM.” In the process, they report CCR5 IC50 activity data for 30 selected analogues. 22 of those compounds show sufficient potency to merit intrinsic clearance testing in human liver microsomes (HLM). Subsequently, 17 of the 22 compounds pass on to hERG inhibition assaying.
The hERG Anti-target
The hERG potassium ion channel mediates normal heart function, and blockage of the hERG channel can increase the risk of life-threatening arrhythmias. Because a wide range of pharmacophores inhibit the hERG channel, hERG antagonism is a common contributor to the failure of preclinical drug safety trials. As such, hERG channel “antiselection” is a crucial lead optimization objective for small molecule discovery programs.
The ability to computationally assess the hERG inhibition of a compound is therefore highly valuable to discovery scientists. With a reliable hERG predictor tool, a discovery team can avoid chemical space and structural motifs that are hERG liable and focus time and resources elsewhere. While the perfect in silico hERG inhibition predictor does not exist, the actionability of hERG models has improved over the past two years due to advances in applying graph-based neural networks to molecular property prediction.
The OpenBench Lab
The OpenBench Lab puts the state-of-the-art in machine learning (ML) for molecular property prediction at drug hunters’ fingertips. The Lab applies the latest research coming out of academic institutions like Stanford and MIT to data sets curated from scientific literature to ensure discovery teams have the best available predictions waiting for them “out of the box.” Even when bringing the best ML tools to bear, predicting biologically complex properties like hERG inhibition can be a difficult task, especially in novel chemical space.
Nevertheless, we stake the Lab’s utility on its ability to perform a compound curation and prioritization function on new chemical entities. To that end, this study tracks whether the OpenBench Lab’s ranking of compounds’ hERG affinity matches rankings derived experimentally. If OpenBench’s in silico results consistently align with in vitro hERG measurements, we contend that discovery scientists can improve the efficiency of their optimization programs by using the Lab to prioritize which compounds to synthesize and assay in the wet lab.
Enforcing Generalizability
To judge the OpenBench Lab’s performance inferring hERG IC50 in unseen chemical space, we use the AstraZeneca compounds from Cumming et al. as a reference test set. We intentionally subset OpenBench’s hERG training data to only include those compounds with a Tanimoto similarity of less than .25 when calculated pairwise with all 17 compounds on which Cumming et al. report hERG values. According to Martin Martin et al. (2019) of the Novartis Institute for Biomedical Research, a median average Tanimoto similarity between the training and test set of .34 is “realistically novel” and “comparable to the novelty of compounds actually selected from virtual screens.” We take things a step further. With our approach, the median average Tanimoto similarity between training compounds and the test set is .13. This enforces an analysis of predictive performance on radically novel chemical space.
We consider the Tanimoto similarity-restricted training scenario the base case against which we benchmark “out of the box” generalizability and performance. The single training molecule in the base case scenario most similar to reference test chemical space is depicted above. You’ll note that it shares no apparent overlap in structure to Compound 1. Following the chronology implied by the numbering of compounds in Cumming et al., we propose two further training iterations that incorporate a sparse sampling of the novel chemical space into the training data. In the first iteration, the experimental hERG measurement of Compound 1 is included in the trained model. In the second iteration, empirical hERG inhibition values reported for analogues 3b, 3c, 3e, (S)-3g, and(S)-3h are added as well. In all three training scenarios, the test set only includes Cumming et al. compounds that are not in the training set.
Training Scenarios
Base Case: Literature compounds with Tanimoto similarity < .25
Iteration One: Base Case + Compound 1
Iteration Two: Base Case + Compound 1 + analogues 3 and (S)-3
Stacking Up
We judge the quality of OpenBench hERG predictions using the Spearman rank correlation statistic and associated one-sided correlation test (calculated using R’s stats::cor.test function with alternative = “greater” and method = “Spearman”). The Spearman statistic (ρ) and related hypothesis test compute the association between the ordinal ranking of paired samples. In our case, these pairs are experimental IC50 values reported in Cumming et al. and predicted hERG affinities generated by the OpenBench Lab. The Spearman coefficient ranges from -1 to 1, where a value of 1 means that the ranked ordering of the paired samples perfectly align. A Spearman coefficient of -1 indicates a perfect inverse correlation.
The Spearman coefficient offers a statistically principled generalization of a common sense idea echoed by discovery scientists looking to prioritize which structural hypotheses to synthesize and test:
I just need a ranked list. Give me the relative ranking for a set of fifteen compounds and let me know if I can feel pretty confident that the top 5 are going to turn out to be among the best compounds for the metric of interest.
The higher the Spearman coefficient, the higher the confidence a chemist can have that top predicted compounds rank among the best experimentally.
In this case study, we expect the hERG liability rankings generated in vitro and in silico to be positively correlated. The closer Spearman’s ρ is to 1, the better the OpenBench prediction aligns with experimental results. The one-sided Spearman correlation hypothesis test derives a p-value that is the probability that the rank correlation would occur assuming there is no underlying positive relationship between predicted and experimental results. If that p-value is less than .05, we can reject the null hypothesis that there is no positive correlation between predicted and empirical results.
Analyzing Performance
I. The Base Case
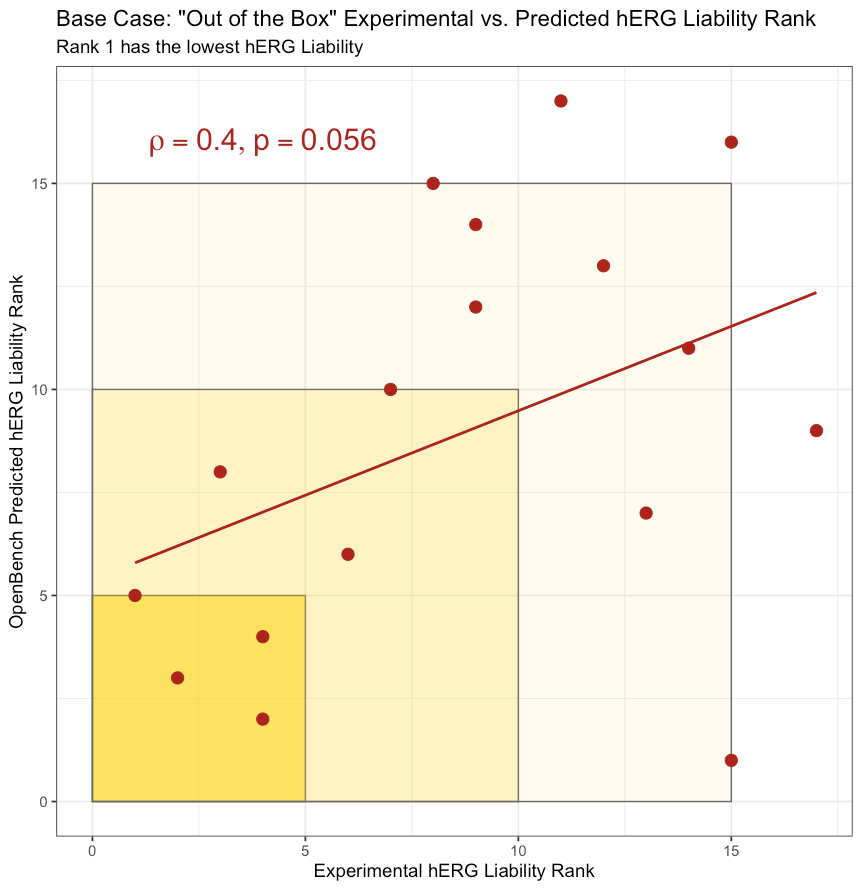
In the figure above, experimental and predicted hERG liability ranks are plotted against each other for the Base Case in which the predictive model is trained only on compounds with low chemical similarity to test compounds (Tanimoto similarity < .25). The base case gives a sense of the OpenBench Lab’s performance when predicting hERG for a truly novel chemical series “out of the box.” An apparent positive correlation between predicted and empirical rank exists, and the Spearman correlation rank coefficient for the base case model is ρ = .4. The null hypothesis cannot be rejected at a significance level of .05 (p=.056); nevertheless, 4 out of the top 5 compounds experimentally determined to be most hERG favorable are among the top 5 compounds predicted by OpenBench. For a quick visual confirmation of top 5 performance, one can count the number of points inside the darkest gold box in the figure above.
II. Iteration One: Base Case + Compound 1

In Iteration One, a single compound from the novel chemical series is added to the training data set. By incorporating the empirical hERG value reported for Compound 1 into the model, the Spearman coefficient on the test set improves from .4 to .52, which is statistically significant with a p-value of .019. In the figure to the right, one can see that, again, 4 out of 5 of the most hERG favorable compounds determined experimentally are captured among the top 5 by the model. Furthermore, all of the top 6 most favorable compounds fall among the top 7 OpenBench predictions.
III. Iteration Two: Base Case + Compounds 1, 3b, 3c, 3e, (S)-3g, (S)-3h

Iteration Two incorporates an additional 5 analogues from the novel chemical series into the training set. As a result, the Spearman’s ρ climbs higher still, from .52 to .83, which is significant with a p-value of .001. All five of the top five most favorable hERG compounds determined experimentally are also in the top 5 compounds predicted by OpenBench, marking perfect performance on the “top 5” heuristic task.
Conclusion
Two principles govern a predictive model’s utility in drug discovery: (1) its generalizability to unseen chemical space and (2) its ability to integrate into existing workflows. A good tool gives actionable predictions in new chemical space and improves its predictions as novel space is sampled experimentally. In this illustrative anecdote produced using a lead optimization undertaken by Cumming et al., the OpenBench Lab appears to achieve high marks on both criteria.
When trained using data from a restricted chemical space different from that of the test compounds, the Lab’s hERG model is able to generalize fairly well to the test set, enough so that 4 out of the top 5 experimentally determined compounds were captured in the top 5 compounds predicted by the model. Incorporating six empirical data points into the model in an iterative fashion that reflects lead optimization cycles, the model performance achieves perfect performance on the “top 5” task and high alignment between predicted and empirical rank as measured by a Spearman coefficient of .83.

Drawing the conclusion that lead optimization efficiency can be improved in all cases by using the OpenBench Lab would be premature based on the information presented in this case study alone. Nevertheless, this illustrative anecdote stands firm in its own right. In the hypothetical where Cumming et al. had access to the OpenBench Lab, they could have benefitted from significant efficiencies by prioritizing compounds to assay based on output from the hERG model. By choosing to assay only the top 50% of compounds deemed least hERG liable by the OpenBench Lab, they could have successfully captured all compounds meeting their >30 μM hERG IC50 criteria while substantially reducing their hERG assay bill.
This case example just scratches the surface of the efficiency that can be gained by integrating high-performing computational models into drug discovery workflows. In part 2 of this CCR5 antagonist case study, we will dive into the multi-objective optimization problem of balancing hERG affinity and human liver microsomal stability in a lead optimization effort. To read part 2, subscribe to the ADME Talks newsletter: