
How Much Can I Save, and at What Cost?
Making QSAR metrics more intuitive to avoid Pyrrhic victories

ADME Talks is a newsletter democratizing the cutting edge in virtual ADME-Tox, pun intended.
As always, we share our analysis in the OpenBenchmark Github. The companion notebook for this piece can be found here:
Were you forwarded this post? Please subscribe:
Executive Summary
Responsible adoption of in silico tools in drug discovery workflows requires a principled assessment of the associated risks. This edition of ADME Talks proposes a framework for measuring the practical value of computational models that is more intuitive, scenario specific, chemist-friendly, and risk-forward than traditional statistical metrics. We call this metric “three 9s” performance, and it reflects a model’s ability to curate a compound list with 99.9% confidence that the top compounds along the filtered dimension will be captured.
To get the most out of computational approaches, discovery scientists must first understand what these approaches are capable of. A better understanding of model capacity can help articulate the most promising in silico use cases and encourage the confident application of computational tools in small molecule drug discovery. To learn more about leveraging your in-house data assets to build a resource efficient and confident in vitro / in silico discovery strategy, visit the OpenBench website:
Introduction
How much money can my discovery program save by using your predictive platform?
This is a question we hear a lot at OpenBench. It’s one we like to field—but often, when I hear it, my immediate reaction is:
We’ll have no problem saving you money … But at what cost?
Drug discovery is a line of work in which being penny wise can very quickly translate into being pound foolish. Slashing your ADME-Tox bill by 90% using computational models sounds nice in a vacuum, but could amount to a Pyrrhic victory if it results in promoting the wrong asset into animal testing or the clinic.
Pyrrhus of Epirus, namesake of the Pyrrhic victory

After suffering heavy losses in a victory at the Battle of Asculum in 279 BC, Pyrrhus of Epirus stated his tragic paradox: that one more such victory would ruin him entirely. In a similar way, “victories” inflicted by the misuse of in silico tools could render a discovery program utterly ruined. Given the slim margin for error in drug discovery and the relatively low cost of conventional ADME-Tox characterization, it would be foolish indeed to miss a compound that could have become your drug based on poor in silico ADME-Tox characterization.
To use computational models effectively, it is of utmost importance that users understand what they are capable of. As long as in silico models have existed, it has been common practice to benchmark their utility using statistical metrics. Metrics like the coefficient of determination (R^2) are necessary and useful for comparing model performances across different algorithms, feature sets, and parameter combinations. When the time comes, however, for the practical application of QSAR models in a drug discovery setting, an R^2 value without additional context fails to communicate practical utility or express the overhead risk to using computational approaches.
To solve this problem, I propose a metric framework that can be applied to QSAR modelling for library screening and curation. The major advantage to the metric: that it enables confident, risk-assessed in silico/in vitro strategies by explicitly articulating resource savings in terms of attendant risk. Using this metric, we can reduce the likelihood of blundering into Pyrrhic victories by misusing computational tools.
“Three 9s” performance
Borrowing a concept from reliability engineering, we use “three 9s” performance to designate the amount of resources one could save by curating a compound list quantitatively while maintaining 99.9% (hence “three 9s”) certainty of capturing a subset of interest.
To illustrate this idea, consider a toy example. Imagine you have a list of 1,000 compounds for which you would like to know the 5 with lowest intrinsic clearance (CLint) in human liver microsomes (HLM). A conventional—if brute force—approach may be to assay all 1,000 compounds. Leaving aside a discussion about the noise inherent to in vitro assaying for now, it is convention to accept the proximate conclusion that the lowest 5 experimental results have the true lowest metabolic clearance in your list.
Consider now this same task undertaken in conjunction with an HLM CLint model like the one offered free out-of-the-box in the OpenBench Lab. To assess “three 9s” savings, it is possible to simulate experimental and predicted values drawn from a distribution with an R^2 equal to .46. If we run 10,000 simulated trials, each generating such simulated experimental and predicted properties for the 1,000 compounds in the list of interest, we can determine “three 9s” performance by taking the 99.9th percentile of the lowest ranking predicted for the top 5 experimental values generated in each trial.
Jupyter notebook output of “three 9s” simulation as devised above

Running a simulation as described, we see the 5 most favorable compounds by CLint will be captured among the top 758 compounds predicted by the model in 9,990 out of 10,000 cases. Given this outcome, we say our HLM model has a “three 9s” cost savings of 24.2% since 242 out of 1,000 compounds can be safely excluded in 99.9% of cases. This may be a modest cost reduction, but one that can be made with a confident understanding of the downside risk involved.
From “three 9s” to “n 9s”
One advantage to the “three 9s” principle is that it can adapt to any risk appetite. If you’re happy with mere 90% certainty that you’ve captured the subset of interest in an exploratory screening, use “one 9” savings. If you need greater certitude, use “five 9s.” Following the scenario outlined above, at a “one 9” risk appetite one could save 64.6% of their HLM bill. A “five 9s” risk appetite would have anyone sleeping soundly at night, but only net a 5.2% savings. Weighing this trade-off is a user-by-user and budget-by-budget consideration. The higher your risk appetite, the more resource saving potential, but the more likely you are to achieve a Pyrrhic victory. What’s important is striking a balance according to program budget restrictions and risk appetite.
In the table below we see precisely encapsulated the question “How much can I save—and at what cost?” As a rough heuristic for this scenario, a 10x better risk profile will come with a ~2-fold decrease in savings rate.
“n 9s” cost savings in trying to capture top 5 out of a library of 1000 compounds using a model with R^2 = .46

Putting “n 9s” into practice
When the question of cost savings comes up at OpenBench, our standard response, while comprehensive and truthful, is a bit tedious to unpack:
Cost savings are a function of the Lab’s predictive capacity, how many compounds your group needs to characterize, your use case, and your unit cost of assaying that property in vitro.
Our standard response reflects that several factors influence “n 9s” savings, and an analysis of each dimension can help elucidate where the most promising cost saving opportunities exist given the current state-of-the-art in virtual ADME-Tox.
Better model performance improves “n 9s” savings
The better the statistical performance of a model, the more savings it delivers for a given risk appetite. If this weren’t the case, I would be worried about the robustness of the “n 9s” metric! To see this principle in action, consider the visualization below:
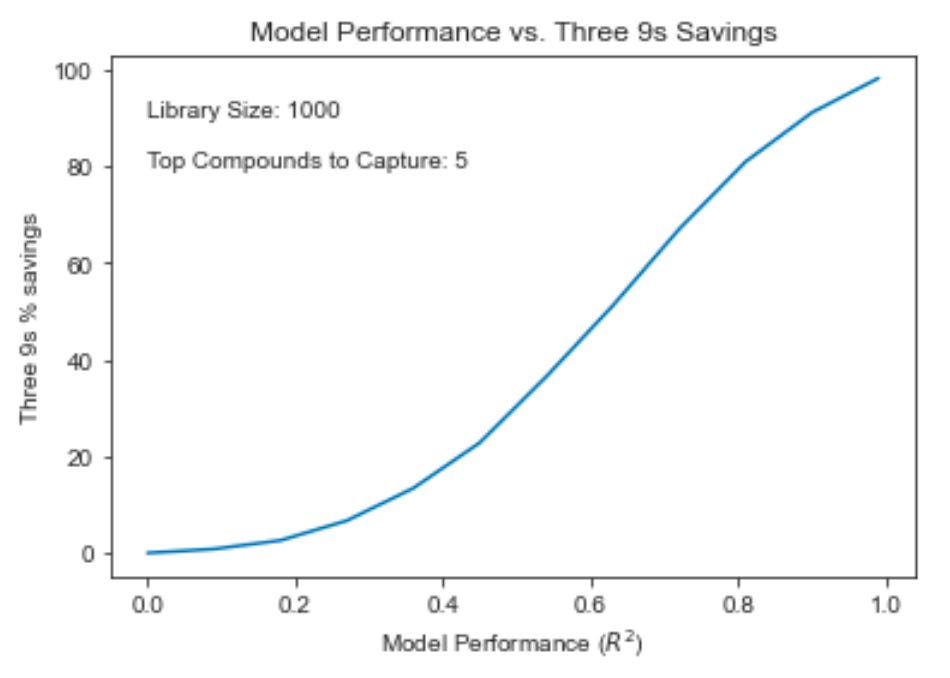
As a rule of thumb—following an example set by Martin et al. (2019)—we try to achieve an R^2 ≥ .3 benchmarked on a 10-fold cross-validated scaffold-split before hosting a given model on the free version of the OpenBench Lab. Admittedly, a couple of our under construction CYP inhibtion models don’t currently meet that standard. Nonetheless, it seems appropriate that the .3 threshold corresponds to about 10% “three 9s” savings in the scenario above, offering reasonable utility out-of-the-box. To improve on what’s available out-of-the-box, we encourage organizations to leverage their in-house data using the OpenBench platform. The more high quality data that is incorporated into model training, the better the models tend to perform on predictive tasks.
The larger the screening library, the more “n 9s” savings potential
Here we see “three 9s” savings plotted against library size for a range of examples from a one compound library to a 10,000 compound library. As the library grows, the model is able to have more and more impact on the challenge of picking out the top compound. In this chart, we use the R^2 from the HLM example (.46) and reduce the # of compounds to capture to 1 to make sense of the library size range at every step.
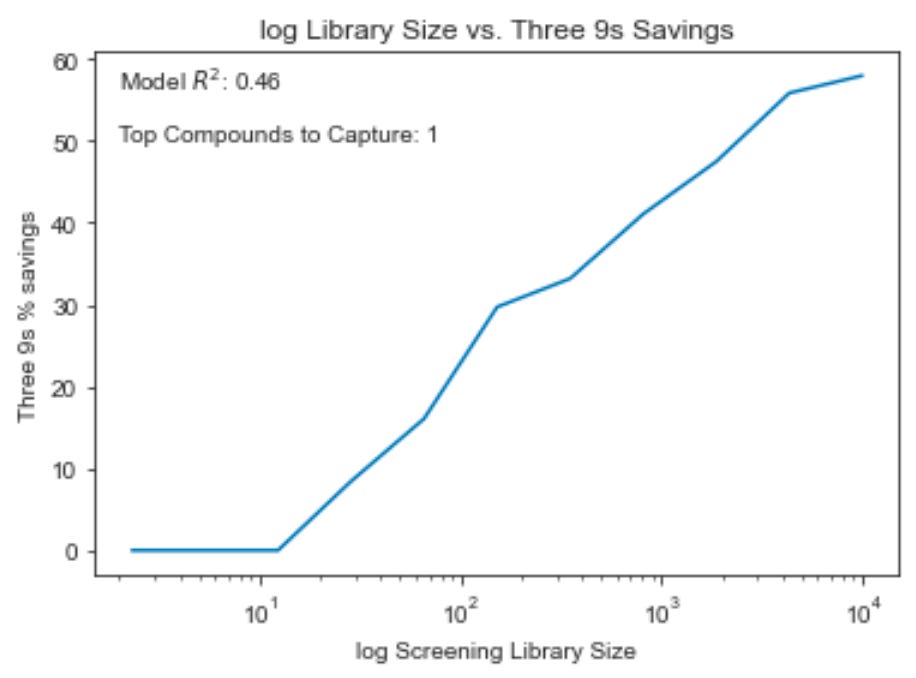
You’ll note that in these simulations “three 9s” savings is 0% on libraries smaller than ~20 compounds, which may obviate certain use cases for in silico tools, particularly in lead optimization settings. A higher quality model would be necessary to make a “three 9s” confident curation impact on such a short compound list. On the other hand, nearly half of a 1,000 compound library could be excluded while retaining 99.9% confidence that the top compound is among those kept, even with modest model performance. Virtual high-throughput screens seem to carry more promise than lead optimization use cases with current tools.
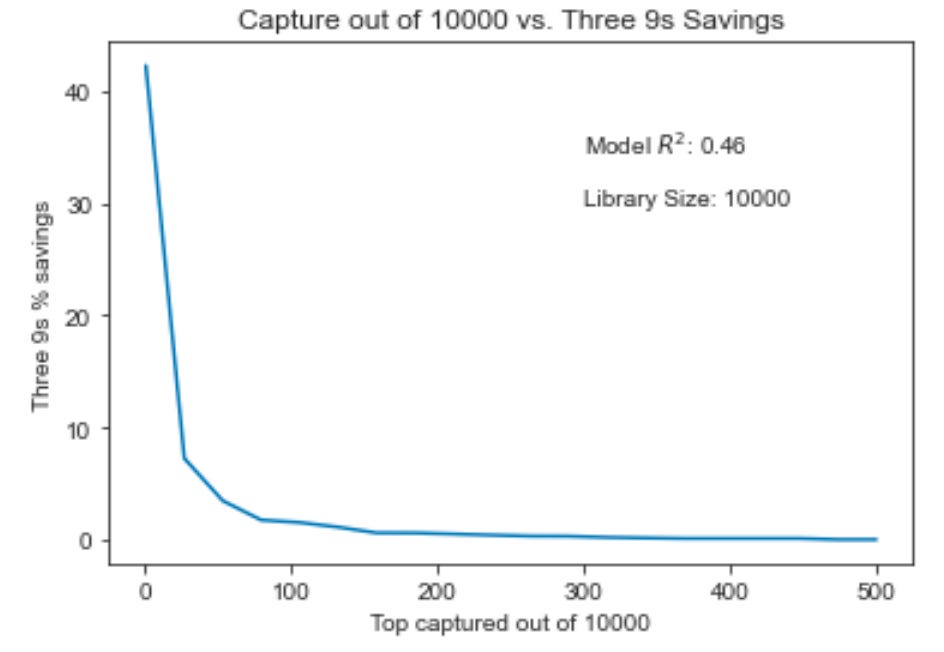
The larger the top n subset we want to capture, the more it will cost
Holding model performance constant, it is much more difficult to capture the top 100 compounds from a library than it is to capture the top 10. In general, savings drop off substantially the more top compounds we want to capture with “n 9s” certainty. Thankfully, for most drug discovery use cases, capturing a select, small subset of top compounds is precisely the goal.
Discussion and Limitations
The virtuous in silico -> in vitro cycle
In many of the examples here, we used the OpenBench Lab’s “out-of-the-box” performance on HLM stability (R^2 = .46) to seed the simulations. You could use this model for free within minutes by signing up to the OpenBench Lab. This baseline model performance offers real value according to the “three 9s” metric, especially in screening scenarios where the library in question is sizable.
An important thing to note, of course, is that a model’s performance does not stay stagnant. With the inclusion of additional high quality training data, performance can improve dramatically, especially in proprietary chemical space. As few as half-a-dozen training examples can make a big difference. Our case study on predicting hERG in novel chemical space proves this point, witnessing R^2 rise from .16 to .67 with the incorporation of just six data points. Over time, as in silico results inform an in vitro strategy, in vitro data in turn feeds back into in silico models, improving the overall efficiency of a tightly coupled approach. Maximally leveraging in-house data resources and encouraging this virtuous cycle is one of the primary advantages of the OpenBench platform.
Scenario specificity
“N 9s” metrics are highly scenario specific and don’t scale up and down linearly. “N 9s” savings when trying to pick the top five compounds out of 100 won’t be the same as picking the single best compound out of 20, even though both are a 1:20 ratio. As such, we hope to host a flexible “N 9s” calculator tool in the Lab soon, where interested users can work backward from their budget to assess the “n 9s” performance of their ADME-Tox strategy. For now, use the Jupyter notebook sandbox calculator or reach out directly if you’d like assistance in assessing your scenario.
Limitation of ranked curation assumption
The “n 9s” metric assumes that ranked curation of compounds is the primary use case for all in silico models. This isn’t the case. Oftentimes, especially for ADME-Tox characterization, ranking is irrelevant as long as long as compounds fall within certain property ranges or above certain thresholds.
It is hard to assess true performance in unexplored chemical space
To construct “n 9s” metrics, we must start with a statistical assessment of model performance. No matter how painstakingly we benchmark our ADME-Tox models to try to give users a sense for our “out-of-the-box” performance in proprietary chemical series, it is difficult to quantify the epistemic uncertainty of a predictive model inferring properties of novel compounds. Put another way, it is hard to know how well we will perform in your chemical space without setting up a retrospective study.
At OpenBench, we pride ourselves on a principled approach to confident cost saving estimation, and it begins with assessing the Lab’s predictive performance in your bespoke chemical space. As such, we currently offer a reduced-cost trial period through October 1st for all companies interested in assessing OpenBench’s performance on their proprietary compounds. To join the growing list of companies embarking on an OpenBench trial, visit the OpenBench website and enter your eMail address.
Conclusion
The emergence of practical metrics will reduce the misuse and abuse of in silico methods and minimize the likelihood of Pyrrhic victories inflicted by intemperate QSAR-based decision making. By the same token, more intuitive metrics will increase confidence in the adoption of in silico methods and encourage their use in scenarios where they can make meaningful positive difference in the allocation of R&D resources. At the end of the day, computational models exist to serve chemistry, biology, and the discovery of life-changing therapeutics. A better understanding of the models themselves can help fulfill this purpose—and it starts with more intuitive metrics like “n 9s” performance.